What the Machine Learning in RX 6 Advanced Means for the Future of Audio Repair Technology
iZotope Senior DSP Research Engineer, Gordon Wichern, writes about the machine learning that was used to develop RX 6 Advanced’s De-rustle and Dialogue Isolate.
You may have heard of machine learning but not exactly understood what the term means, or how we use it in our everyday lives. Machine learning refers to a class of algorithms that discover patterns in data and use those discovered patterns to make predictions when presented with new data. Some of the most familiar applications of machine learning are speech recognition (Siri, Amazon Alexa), where algorithms transcribe the words we speak, or image recognition where algorithms automatically label items, places, and faces in images (think of how Facebook accurately suggests people to tag in uploaded photos, and how your email can automatically recognize spam).
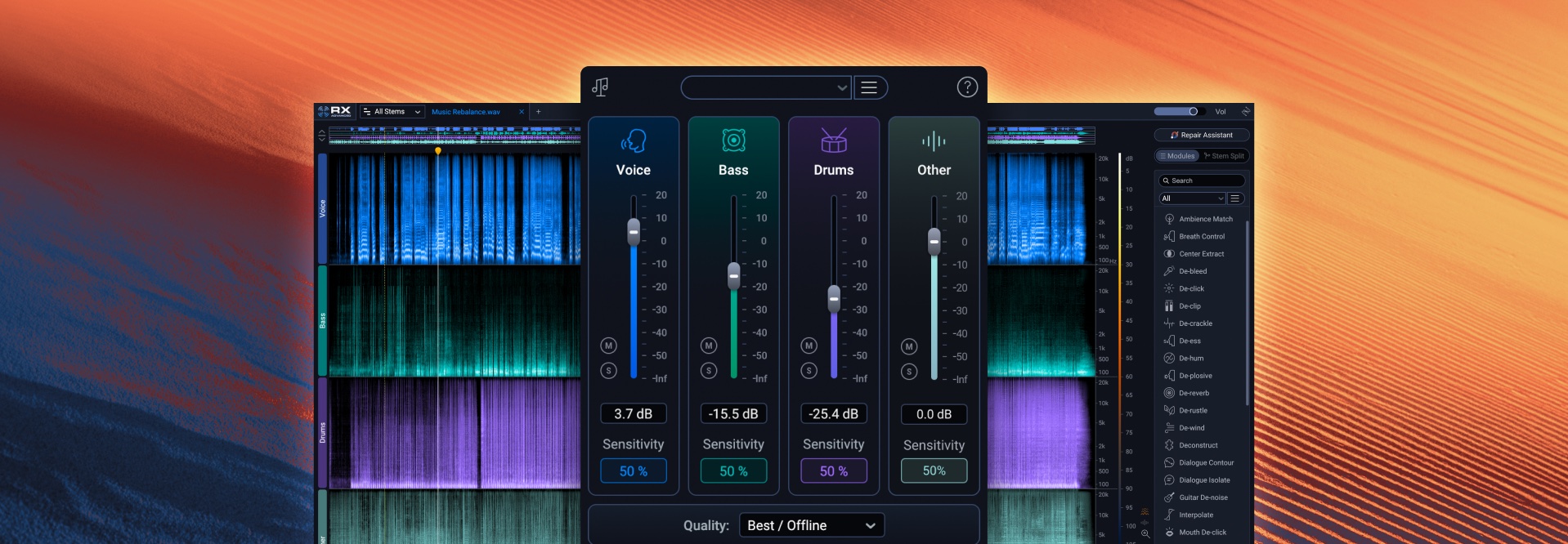
Machine learning is also starting to allow for innovations in the audio industry. At iZotope some of our previous machine learning applications were to automatically identify instruments as part of the Neutron Track Assistant feature, and to automatically detect song structure (i.e., verse/chorus) for improved waveform navigation in the Ozone standalone application.
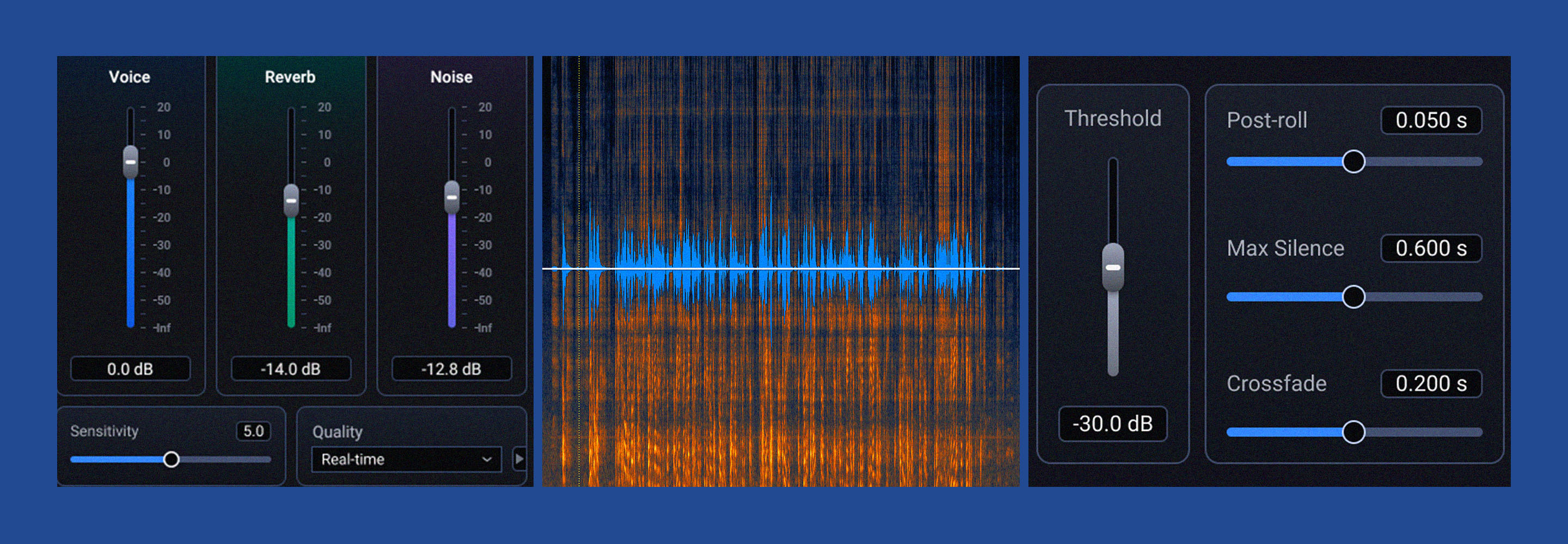
To process audio in RX, our algorithm needs to learn to make a decision about the amount of dialogue present in each pixel of the spectrogram, which corresponds to over 100,000 decisions per second of audio.
Neutron's Track Assistant
What’s common about all of the machine learning applications mentioned above is that they label content but don’t process it, that is to say a speech recognition system doesn’t modify your speech. Two of the modules in RX 6 Advanced—Dialogue Isolate and De-rustle—are actually processing audio using an algorithm trained with machine learning.
Why That Matters for Musicians and Audio Post Production Pros
The challenge with processing audio is that the number of decisions the algorithm needs to make increases dramatically. For example, in Neutron we only need to make a single decision for an entire track of audio—what instrument is playing. To process audio in RX 6, our algorithm needs to learn to make a decision about the amount of dialogue present in each pixel of the spectrogram, which corresponds to over 100,000 decisions per second of audio.
RX 6 Advanced, editor view, with De-rustle open
The current suite of audio repair tools in RX work great for well-defined disturbances, like clicks (short in time) or plosives (always in low frequencies). However, a problem like lav-mic rustle can vary from high-frequency “crackling” to low-frequency thuds or bumps, and change in unpredictable ways based on how a person moves or the type of clothes they wear. This made developing an algorithm to remove rustle in all its variations nearly impossible. With machine learning, we can train a deep neural network to remove all varieties of rustle we can record, even though we may not understand how exactly it’s doing it.
Similarly, the Spectral DeNoiser in RX is truly magical but not designed for highly variable background noise situations like a cheering stadium, a thunderstorm, or background babble and clatter from a restaurant. Machine learning enables the Dialogue Isolate module to minimize these types of highly variable disturbances.
Breath sounds in a vocal recording are another highly variable disturbance, but since they don’t overlap with speech they can be easily removed if we know where they are. The RX 6 Breath Control module uses machine learning to find breaths in a recording and then ducks the gain to remove them.
For producers and audio engineers, these features could mean saving the recording of a live performance, even though someone may have performed a particularly “breathy” take, a plane flew over your apartment in the middle of your otherwise perfect recording, or any number of situations. Machine learning enables the best chance at saving your take we’ve ever had.
The Future of Machine Learning in Audio
Advances in machine learning will hopefully lead to the rescue of more and more audio that in the past would have had to be re-recorded, and performing that rescue will become easier and easier.
As for what the future holds, this is a difficult question to answer, because the field of machine learning (deep learning in particular) is advancing at such a rapid pace. It seems like a great new technique is popularized every couple of months, with some of them being deemed unnecessary a short-time later.
One area that could be exciting is if an algorithm could decide when a piece of audio is just too corrupted to repair without objectionable artifacts and in those cases actually synthesize replacement speech and/or music. Synthesizing audio with machine learning has drawn lots of interest since the WaveNet announcement. The development of machine learning algorithms that can take better advantage of hints and expert knowledge from the human using the software could also be truly revolutionary.